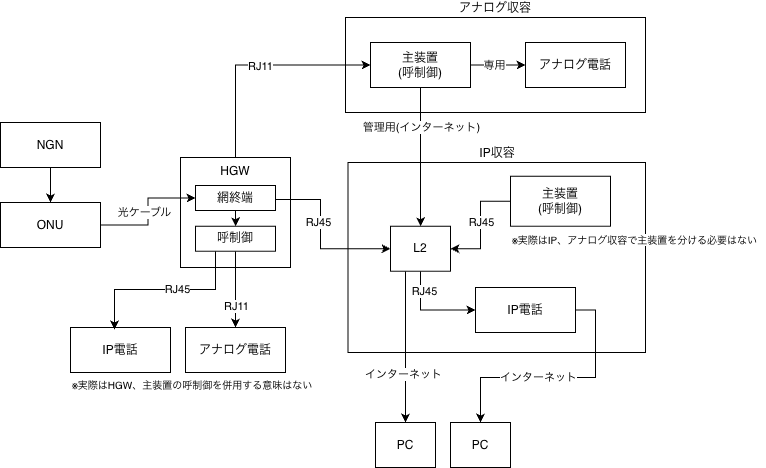
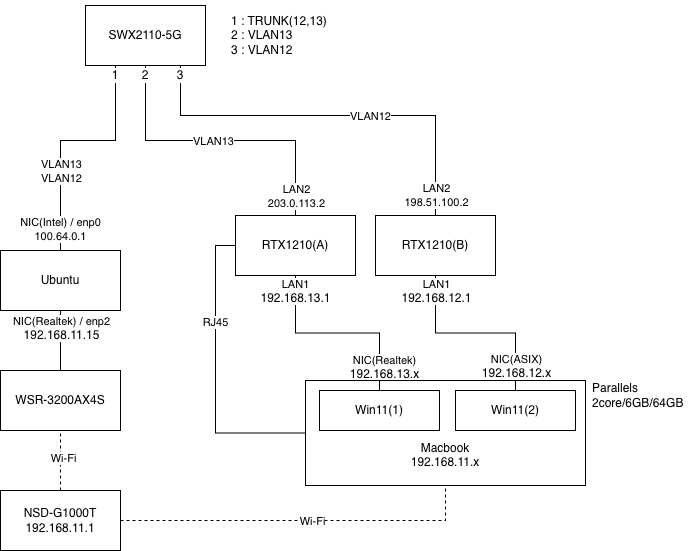
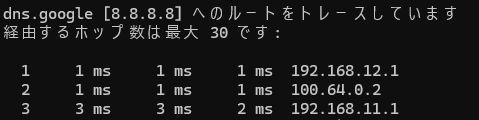
WebGUI設定
初期設定の場合、次のパラグラフのコンフィグ作成、流し込んでからWebで以下を設定する。
ユーザー作成
WebGUI>保守>コマンドの実行>
login user skuser xxx
SSH有効化
WebGUI>アクセス管理>各種サーバーの設定
SSH有効化
※WebGUIでSSHを有効にするとKeyは自動で生成される。
※WebGUIコマンドからは生成できないので以下はコマンドでは実行しない。
sshd service on
sshd host key generate(手動で一度だけのコマンド)
SSH接続
ssh xxx@192.168.xxx.xxx
※SSHクライアントが新しい場合
ssh -oKexAlgorithms=+diffie-hellman-group14-sha1 -oHostKeyAlgorithms=+ssh-rsa xxx@192.168.xxx.xxx
管理権限昇格
administrator
>空白
パスワード設定
administrator password
>xxx
login password
>xxx
ログアウトタイマー
user attribute skuser login-timer=7200
コンフィグ記入
表示設定
console character en.ascii
console lines infinity
アクセス範囲指定
httpd host 192.168.5.0-192.168.5.255 192.168.113.0-192.168.113.255
sshd host 192.168.5.0-192.168.5.255 192.168.113.0-192.168.113.255
名前なしユーザーをシリアル限定
user attribute connection=serial
PPTP/L2TP/TELNET
デフォルト
※httpd / 有効 / lan
※telnetd / 有効 / any
※sshd/pptp/l2tp / 無効
pptp service off
l2tp service off
telnetd service off
Defaultgateway
ip route default gateway <>
pp 1
dhcp lan2
xxx.xxx.xxx.xxx
tunnel 1
ローカルブレイクアウト
ip route default gateway tunnel 1
ip route <他拠点グローバルアドレス> gateway <ローカルWANアドレス>
他拠点のアクセスしたいセグメント
ip route 192.168.xxx.0/24 gateway tunnel 1
ローカルブレイクアウトしたいアドレス
ip route xxx.xxx.xxx.xxx gateway <ローカルWANアドレス>
LAN1 Address
ip lan1 address <>
xxx.xxx.xxx.xxx/24
LAN2 Address
ip lan2 address <>
dhcp
xxx.xxx.xxx.xxx/xx
pp select 1
DNS
dns server <>
xxx.xxx.xxx.xxx(NURO Bizなど指定のアドレス)
xxx.xxx.xxx.xxx(拠点間VPNで他拠点抜けの場合、他拠点のローカルアドレス)
pp 1
※プライベートアドレスの問い合わせを外部に漏らさない
dns private address spoof on
dns service <>
recursive
off
自身がクライアントからのDNS問い合わせを受け付けるかどうか。
※recursiveが初期値
dns server xxx.xxx.xxx.xxx
DNSの問い合わせ先
dns serverの設定で、拠点間VPNをFQDNやネットボランチDNS名で書いている場合、トンネルを張るには名前解決が要る、名前解決にはDNSが要る、DNSにはトンネルが要るデッドロックになる。
dns host 192.168.0.0-192.168.255.255
DNS問い合わせの受け付ける範囲
NAT
ip lan2 nat descriptor 1000
nat descriptor type 1000 masquerade
nat descriptor address outer 1000 <>
ipcp / PPPoE
primary / DHCP
xxx.xxx.xxx.xxx / 静的IP
※これはデフォなので不要
nat descriptor address inner 1 auto
・NAT配下のIPsec終端
nat descriptor masquerade static 1 1 xxx.xxx.xxx.xxx udp 500
nat descriptor masquerade static 1 2 xxx.xxx.xxx.xxx esp
nat descriptor masquerade static 1 3 xxx.xxx.xxx.xxx udp 4500
DHCP
dhcp service server
dhcp scope 1 192.168.xxx.2-192.168.xxx.254/24
dhcp server rfc2131 compliant except remain-silent
PP
※ 起動
pp select 1 ~ pp enable 1
※ 基本
pppoe use lan2
pp auth accept pap chap
pp auth myname (ID) (PASS)
ip pp nat descriptor 1000
※ 常時接続
pp always-on on
pppoe auto disconnect off
※ mtu / mru / mss
ppp lcp mru on 1454
ip pp mtu 1454
ip pp tcp mss limit auto
※ IPCPで貰うペア
ppp ipcp ipaddress on
ppp ipcp msext on
※ 圧縮なし
ppp ccp type none
拠点間VPN
ip route xxx.xxx.xxx.xxx/24 gateway tunnel 1
ipsec auto refresh on
※ 起動
tunnel select 1 ~ tunnel enable 1
※ トンネルIPsec紐づけ
ipsec tunnel 1
※ 暗号方式
ipsec sa policy 1 1 esp 3des-cbc sha-hmac
※ 認証手段
ipsec ike pre-shared-key 1 text xxx
※ 相手
ipsec ike remote address 1 xxx.xxx.xxx.xxx
<条件付必須>
※ 両側グローバルIPなら不要
ipsec ike nat-traversal 1 on
ip tunnel tcp mss limit auto
ipsec ike keepalive use 1 on heartbeat 10 6
ipsec ike local address 1 xxx.xxx.xxx.xxx
<以下なくてもOK>
※ メモ
description tunnel test
※ ログ量
ipsec ike keepalive log 1 off
その他
MTU/MRU/MSS
MTU
IP層で送信できるIPパケット全体サイズ
1454
MRU
PPP層で自分が受信できる最大サイズ
1454
MSS
TCP層でデータ部分の最大サイズ
MTU-40